
Quantum Variable-Length Deduplication
Data deduplication has revolutionized the datacenter, improving data protection and reducing storage costs. Today, there are more ways than ever to leverage data deduplication; from flash arrays, to backup applications, and of course disk backup appliances—so what are key considerations when selecting deduplication technology?
What is Variable-Length Deduplication?
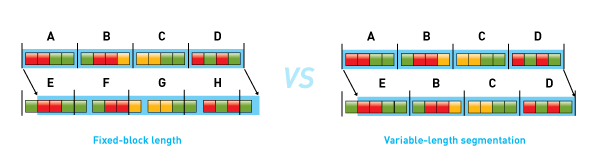
The purpose of data deduplication is to increase the amount of information that can be stored on disk arrays and to increase the effective amount of data that can be transmitted over networks. There are plenty of algorithms designed to reduce data, from compression algorithms to different ways to deduplicate redundant bits or blocks of data to reduce the data written to disk. Primary methods are file-based or that may use fixed-length data segments or variable-length deduplication.
Data deduplication used and implemented by Quantum is the specific approach to data reduction built on a methodology that systematically substitutes reference pointers for redundant variable-length blocks (or data segments) in a specific data set.
Quantum’s deduplication technology divides the data stream into variable-length data segments using a data-dependent methodology that can find the same block boundaries in different locations and contexts. This block-creation process allows the boundaries to “float” within the data stream so that changes in one part of the data set have little or no impact on the boundaries in other locations of the data set. Through this method, duplicate data segments can be found at different locations inside a file, inside different files, inside files created by different applications, and inside files created at different times.
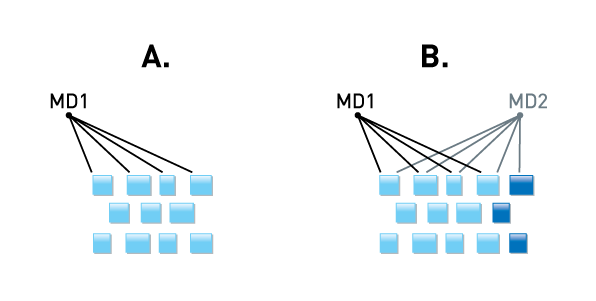
The Data Reduction Difference
Improving deduplication 3x reduces storage, network and cloud costs
Ultimately the amount of data reduction can vary dramatically depending on the deduplication algorithm and characteristics of the data from 50% reduction (2:1 ratio), all the way up to 99% reduction (100:1 ratio) or more using variable-length deduplication. Since the benefit of deduplication is two-fold: (1) reduce data stored on disk, and (2) reduce network traffic (LAN or WAN), a 2x or 10x difference in data reduction can have very material impact to storage, network and cloud costs.
Quantum’s patented (USPTO #5,990,810) variable-length method is the most efficient way to deduplicate common data center data – 3x more efficient than fixed-block approaches.
When deduplication is based on variable-length data segments, data deduplication has the capability of providing greater granularity than single-instance store technologies that identify and eliminate the need to store repeated instances of identical whole files. In fact, variable-length deduplication can be combined with file-based data reduction systems to increase their effectiveness.
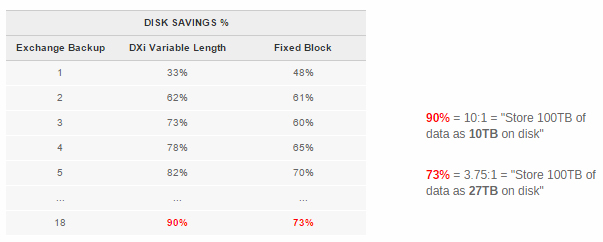
The chart above illustrates the difference – this chart shows the results of completing 18 sequential backups of a Microsoft Exchange environment, then shows the disk savings % over those 18 backups for both DXi® variable-length deduplication, and a fixed block deduplication algorithm. The results show that after 18 backups, variable-length deduplication reduces disk requirements by 90%, whereas fixed block only reduces the data by 73%. In real-world terms, this means variable-length deduplication stores the same data on one-third of the disk capacity of a fixed block approach!
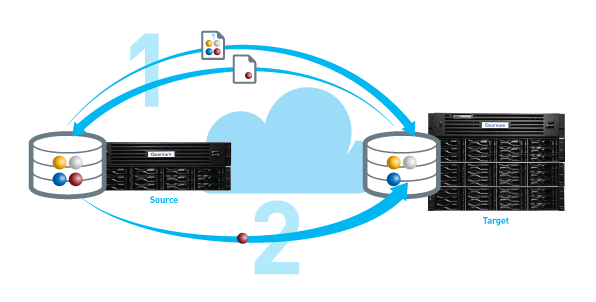
Deduplication-Enabled Replication
Moving data off-site and in the cloud
Deduplication was originally designed as a technology for backup and disaster recovery, a technology that would reduce or eliminate tape’s use for backup. And it’s great as a backup technology, since backup data contains a lot of redundant data sets over time. But deduplication has enabled so much more than just data reduction – it’s becoming a fundamental cloud technology.
Data deduplication makes the process of replicating backup data practical by reducing the bandwidth and cost needed to create and maintain duplicate data sets over networks. At a basic level, deduplication-enabled replication is similar to deduplication-enabled data stores. Once two images of a backup data store are created, all that is required to keep the replica or target identical to the source is the periodic copying and movement of the new data segments added during each backup event, along with its metadata image, or namespace.
Variable-length deduplication reduces disk storage, but also dramatically reduces network bandwidth requirements, since only deduplicated data is replicated. This means data can be replicated between sites and to and from the cloud in a very efficient way, a way that minimizes network traffic and costs.
Location Matters: Where to Deduplicate
How deduplication impacts compute resources
All data reduction algorithms have this in common: They use compute / processing power to perform the algorithm, as well as to keep track of the various bits of data. So if users turn on deduplication on primary storage, flash or SSD, that device will consume processing power performing deduplication that won’t be available for other tasks – like serving the clients, applications and users of that storage. And, not only is processing power used during the time when data is initially being deduplicated, but with all algorithms some sort of defragmentation or disk space reclamation process needs to be run to clean up the pool of bits and blocks. This also takes processing power, and again when the device is performing this function, it has less capacity available to perform other tasks. In short, there is no free lunch. The CPU horsepower, RAM, and storage required to perform deduplication has to come from somewhere.
This is why deduplication is best suited as a purpose-built backup technology, and best deployed as an appliance. Backup has evolved over time to be a process that happens during a specific window in the datacenter – during that time backup servers and storage are ‘busy’ – i.e. during the backup window, like at night or over the weekend. But backup storage can afford to ‘sit idle’ outside of backup windows – this is a perfect time for backup appliances to perform those backup tasks that are associated with deduplication, and do it during the time when it won’t impact either backup or production applications.